tcp/ip
MCU
bash
lua __newindex
Flink Sql
社区论坛
内核
prometheus
NPDP
CAS
视频编解码
FANUC机器人
资损
cocos2d
PC
调试助手
Cadence Allegro
选择器优先级
addWaiter
比较运算符
wordcount
2024/4/11 19:09:43
Windows下IDEA运行scala版本的spark程序(踩坑总结)
首先,说一下,一般spark程序肯定都是打包然后放到Linux服务器去运行的,但是我们为什么还需要在Windows下运行spark程序。当然有它的道理: 因为我们很多人都是习惯在Windows系统下编写代码的,所以,如果能在Wi…

运行hadoop自带示例程序wordcount
运行hadoop自带示例程序wordcount
创建 a.txt
[hadoopspark1 ~]$ vim a.txt
spark hadoop spark hadoop yarn resouremanager yarn hadoop
创建 b.txt
[hadoopspark1 ~]$ vim b.txt
1001 aaa 1002 bbb hadoop hadoop1
创建 wordcount/input hdfs的目录
…

Storm的wordcount实战示例
有关strom的具体介绍,本文不再过多叙述,不了解的朋友可参考之前的文章 http://qindongliang.iteye.com/category/361820 本文主要以一个简单的wordcount例子,来了解下storm应用程序的开发,虽然只是一个简单的例子 但麻雀虽小&a…

【Hadoop】MapReduce详解
🦄 个人主页——🎐开着拖拉机回家_大数据运维-CSDN博客 🎐✨🍁 🪁🍁🪁🍁🪁🍁🪁🍁 🪁🍁🪁…

手写MapReduce实现WordCount
水善利万物而不争,处众人之所恶,故几于道💦 文章目录 需求分析编写MapReduce实现上述功能Mapper类Reducer类Driver类 查看输出结果 需求 假设有一个文本文件word.txt,我们想要统计这个文本文件中每个单词出现的次数。 文件内容如下…

Spark系列修炼--入门笔记7
核心内容: 1、Scala IDEA安装过程 2、Spark的3种运行模式 3、Scala IDEA编写Spark的WordCount程序(本地模式与集群模式) 今天学习了用Scala IEDA去编写Spark的第一个程序WordCount,整理一下主要的学习笔记。 一、Scala IDEA的安装过程 直接上截图&a…

spark eclipse写wordcount
安装spark,见上文 http://blackproof.iteye.com/blog/2182393 配置window开发环境 window安装scala 下载scala http://www.scala-lang.org/files/archive/scala-2.10.4.msi 安装即可 window配置eclipse 下载eclipse http://downloads.typesafe.com/scalaide-pack/…
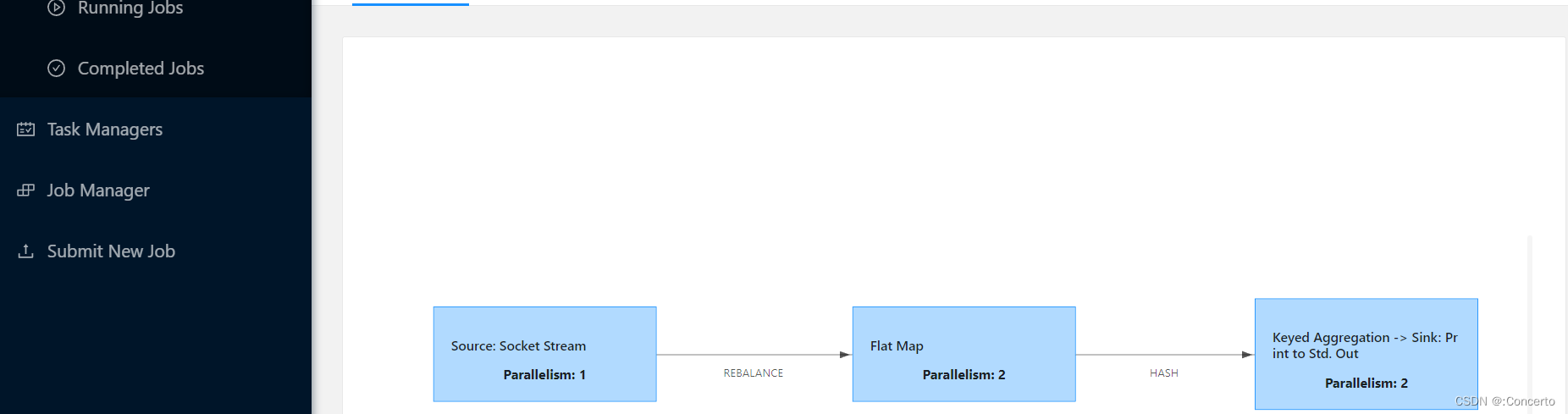
Flink-经典案例WordCount快速上手以及安装部署
2 Flink快速上手
2.1 批处理api
经典案例WordCount
public class BatchWordCount {public static void main(String[] args) throws Exception {//1.创建一个执行环境ExecutionEnvironment env ExecutionEnvironment.getExecutionEnvironment();//2.从文件中读取数据//得到…
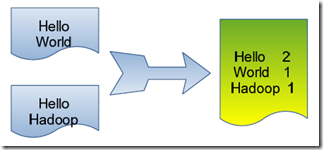
Hadoop之运行wordcount
MapReduce map,映射;reduce,化简。
MapReduce处理大数据集的过程如下图所示 每个MapReduce任务都被初始化为一个Job,每个Job又可以分为两种阶段:map阶段和reduce阶段。这两个阶段分别用两个函数表示,即map…
Scala版本的WordCount
[sizelarge]在处理搜索的同义词数据时遇到一个问题,本来是由数据人员人工整理好的数据,发我直接使用,后来发现发我的数据里面总是存在点问题,也难怪了
2000行x5列条左右的数据,让人工去比对,若不是细心的人…
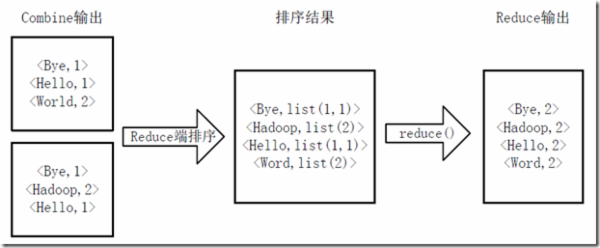
Hadoop之wordcount源码分析和MapReduce流程分析
分析wordcount的源代码,研究MapReduce的运行过程和数据流向。 wordcount源代码 import java.io.IOException;
import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Int…
利用scala书写spark程序实现wordCount
实验环境:虚拟机(centos)上创建了三台集群,部署了Hadoop,words文档放在HDFS上的目录下 所用版本如下: <hadoop.version>2.7.7</hadoop.version> <spark.version>2.4.5</spark.version…
【Flink实战系列】Flink 最简单的 wordcount 示例
在上一篇中已经把flink的集群搭建好了,然后我们就先来写一个wordcount示例,直接看代码吧:
pom文件如下:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-scala_2.11</artifactId><version>1.6.0</version><…
第一个MapReduce程序——WordCount
通常我们在学习一门语言的时候,写的第一个程序就是Hello World。而在学习Hadoop时,我们要写的第一个程序就是词频统计WordCount程序。
一、MapReduce简介
1.1 MapReduce编程模型
MapReduce采用”分而治之”的思想,把对大规模数据集的操作&…
图解shell命令运行Hadoop1.2的WordCount例子
[b][colorgreen][sizex-large]在hadoop1.2.x的版本中,直接运行自带的WordCount的例子会报异常,这个原因是因为它路径的问题,所以,想要正常运行自带的例子,我们还是需要做一些准备工作的,当然你可以直接在ec…
Spark入门之WordCount
[img]http://dl2.iteye.com/upload/attachment/0111/4770/079b7965-40fb-318c-8c35-cd5d6aa03c83.png[/img][sizelarge]环境:
Hadoop版本:Apache Hadoop2.7.1Spark版本:Apache Spark1.4.1
核心代码:[/size][img]http://dl2.iteye.com/upload/…